

UTF-8은 유니코드를 위한 가변 길이 문자 인코딩(변환) 방식이다. 유니코드를 위한 문자 변환 방식에는 UTF-8 이외에도 UTF-16, UTF-32등 여러 가지가 있다. 이렇듯 UTF-8을 이해하기 위해서는 문자열 인코딩과 유니코드를 먼저 알아야 한다.
* 문자열 인코딩 (Character Encoding)
컴퓨터를 사용하는 디지털세계는 모든 것이 0과 1의 디지털 숫자로 변환될 수 있어야 한다. 세계에는 여러 가지 언어와 문자가 있는데 각자 컴퓨터에 표현하는 체계가 다르다. 예를 들어 우리나라가 사용하는 EUC-KR은 한글을 한 바이트(8비트)로 표현할 수 있다. 중국, 일본 등 다른 나라도 이와 유사한 문자 표현 방식이 있다. 이러한 문자 표현을 서로 다른 컴퓨터에서 사용하게 되면 인식이 되지 않는다. 그렇기 때문에 상대방의 표현 체계로 변환시키기 위해서 문자열 인코딩을 수행하게 된다.
예전에는 컴퓨터와 인터넷 성능이 매우 나빳기 때문에 최소한의 바이트로 자신들의 문자를 표현해서 사용하였다. 하지만 기술의 진화로 컴퓨터와 인터넷의 성능이 매우 좋아져서 세상 모든 문자를 표현하는 문자 표현 방식이 대세를 이루고 있다. 그 대표적인 문자 체계가 유니코드이다.
* 유니코드 (Unicode)
유니코드(www.unicode.org)는 전 세계의 모든 문자를 표현하기 위해 설계된 국제산업 표준으로써, UCS(국제문자 세트)라고도 불린다. 유니코드는 UTF-1, UTF-7, UTF-8, UTF-EBCDIC, UTF-16, UTF-32를 포함한다.
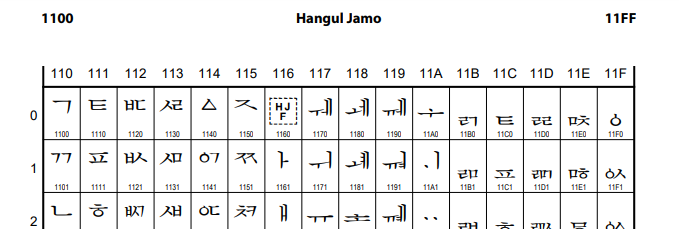
* UTF-8 이란?
UTF-8 은 고정길이의 유니코드 문자를 가변길이의 ASCII로 변환하여 사용하는 알고리즘 변환이다. UTF-8에서 일반 문자는 보통 1바이트로 표현되지만 나머지는 2바이트 이상으로 표현된다. 한 문자에 대한 UTF-8의 최대 길이는 4바이트이다. 즉, 1바이트 ~ 4바이트까지 가변적으로 표현되는 것이다.
참고로, ASCII (아스키 코드)는 영문 문자열을 중심으로 많이 사용하는 문자들을 1바이트로 표현 가능하도록 설계된 문자열 집합이다.

다음은 UTF-8이 어떠한 규칙으로 문자들을 표현하는지 표로 나타내고 있다.
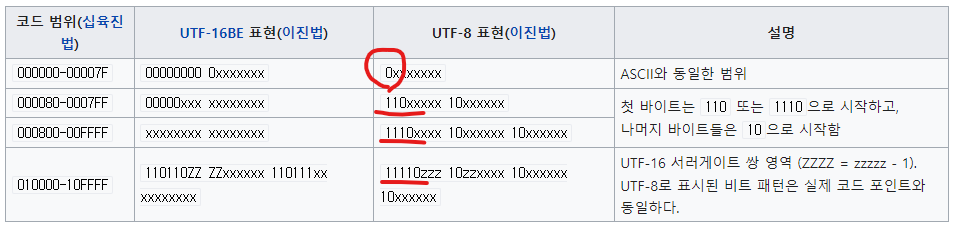
UTF-8은 ASCII의 상위 호환을 보장한다. ASCII가 UTF-8에 속하는 것이다. 이러한 이유로 UTF-8과 ASCII를 헷갈려하기도 한다. 인코딩 방법은 다르지만 문자를 표현하는 코드는 동일한 이유이다.
* UTF-8의 사용 예
UTF-8은 많은 컴퓨터에서 사용되고 있다. 가장 쉬운 예로, 인터넷 주소인 URL을 표현할 때에도 표준으로 사용되고 있다.
예를들어 다음과 같이 한글로 표현되는 인터넷 URL을 갖은 사이트에 들어가 보자.
https://ko.wikipedia.org/wiki/유니코드
사이트에 접속한 후, 인터넷 창의 URL을 다시 복사해서 다른 창에 붙여 넣어 보자. 이상한 표현들로 변환된 것을 볼수 있을 것이다. 이것이 바로 UTF-8 문자열이다. 인터넷 URL은 세계의 모든 사람들이 약속한 문자열로 표현되는데, 그 표준이 UTF-8 이다.
https://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9CUTF-8은 이해하기 쉽게 되어 있으므로 많은 곳에서 사용하고 있다. 한번 공부해서 이해해 놓으면 여러모로 도움이 될 것으로 보인다.